- Introduction and data description
- Relation between price returns and wealth process
- Fitting linear regression
- Conclusion
1. Introduction and data description. Continue the research after updating the data for 2025. In the previous post, we discussed total returns for S&P 500 in detail. Now we discuss bond returns. We take the same data as above, and for bond wealth process 


2. Relation between price returns and wealth process. We derive log price returns from this wealth process using bond math. Then we run linear regression of this log price returns versus rate change. This regression coefficient is called the duration. In continuous setting, this is defined as minus derivative of the log price with respect to the interest rate. More precisely, we use yield to maturity as this interest rate.
Wealth at end of year 








We have 

Since 


3. Fitting linear regression. As mentioned above, the log price returns 





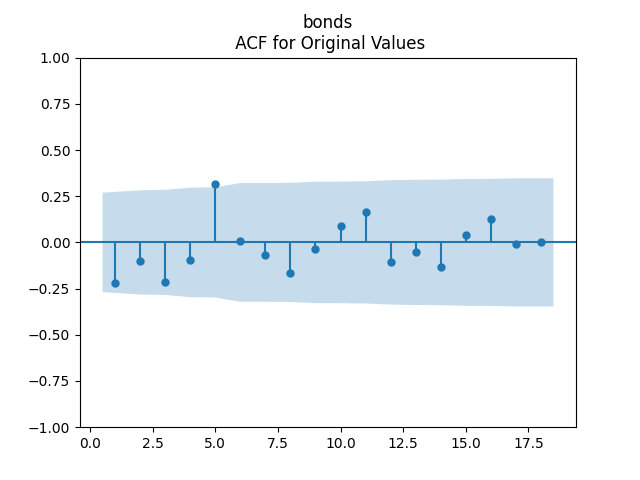
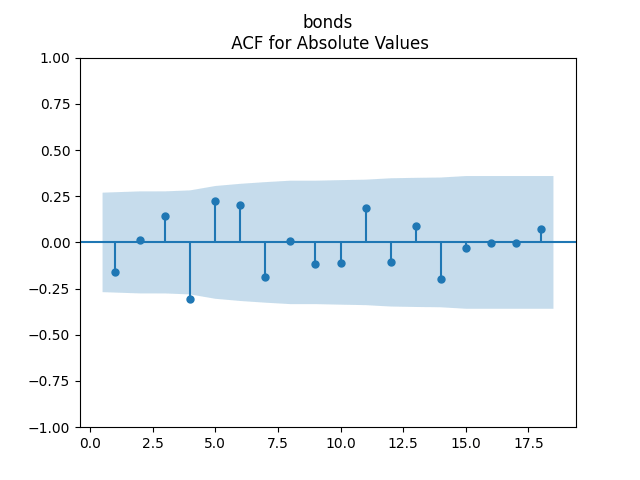
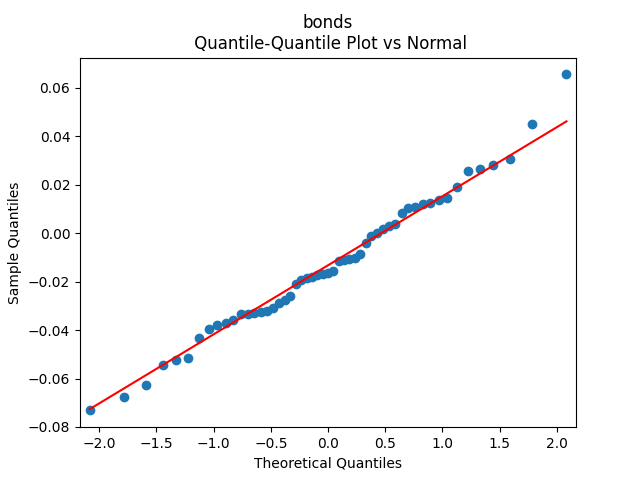
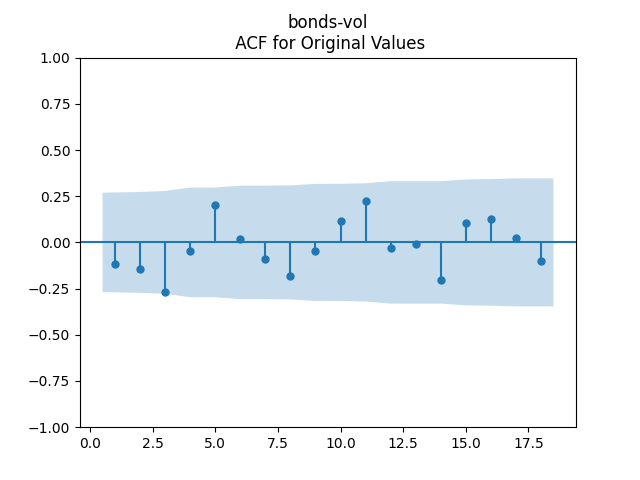
To make residuals independent identically distributed, we divide each term by annual volatility 




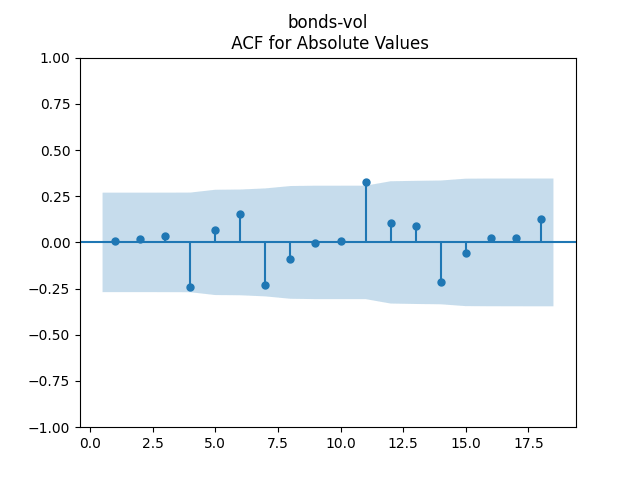
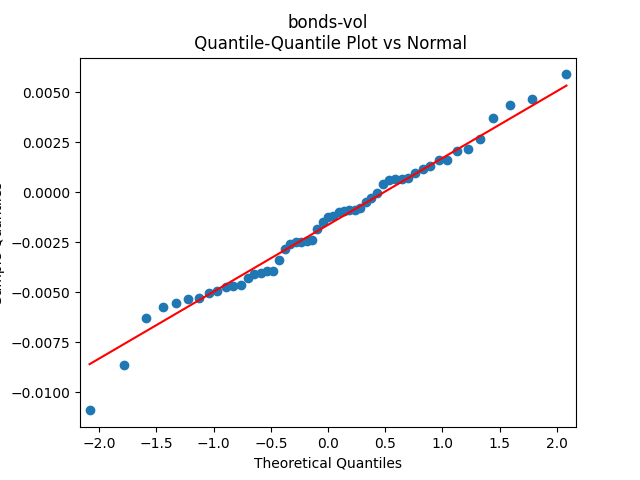
4. Conclusion. We have 


- We clearly explain the meaning of duration as dependence measure of the price upon yield to maturity, and not rely on approximate formulas, such as in this blog post
- We used volatility in our model, but stock volatility used for bond returns is highly unusual
- Residuals are independent identically distributed and Gaussian
Together with the two previous blog posts, we can now create a complete model of:
- BAA rates
- Dividends
- The volatility
- The valuation measure
- Total stock returns
- Total bond returns
These are 6 time series with 5 innovation sequences. Thus we can use it to create a simpler version of the financial simulator.

Leave a comment