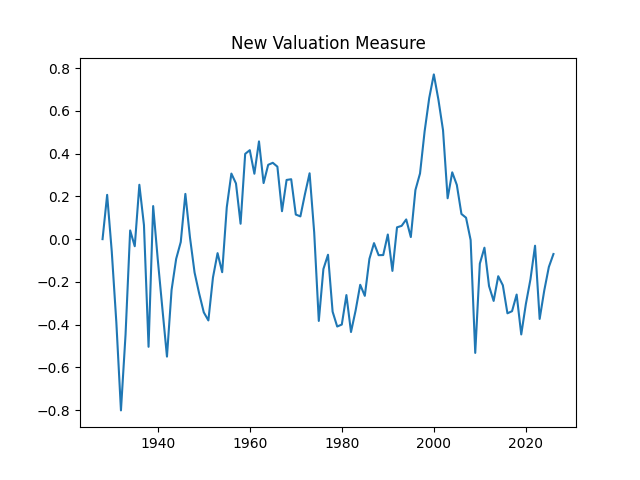
- Motivation of the new valuation measure
- Fit autoregression with linear trend as before
- Use this valuation measure for modeling returns
- Include bond rates and duration
- Conclusion
1. Motivation of the new valuation measure. We continue the previous blog post. We replicate the valuation measure here. We use updated data for 2025. Previously we did this with 10-year earnings but now we wish to do this with 1-year dividends.
We prefer dividends to earnings for the following reasons:
- Dividends are the actual cash paid, and they are not disputable, but earnings depend on accounting standards
- Dividends are more predictable, since companies do not like to cut them, but earnings are highly volatile
- Earnings of companies can be negative, and thus suffer from the aggregation bias, but dividends are nonnegative
2. Fit autoregression with linear trend as before: Take the index level 





We model the cumulative difference 


This can be written as 





From here, we can deduce 

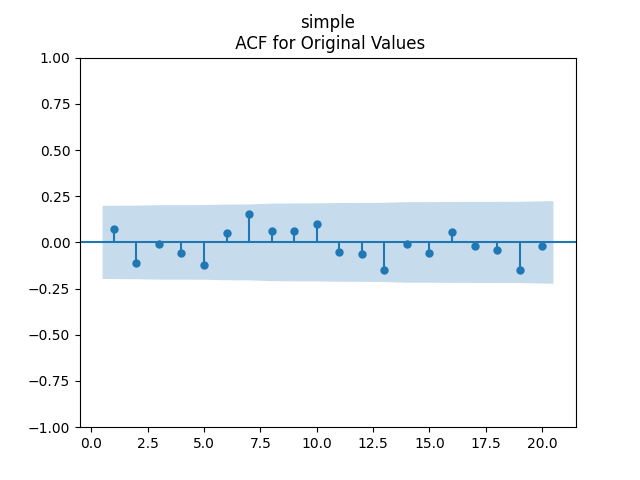
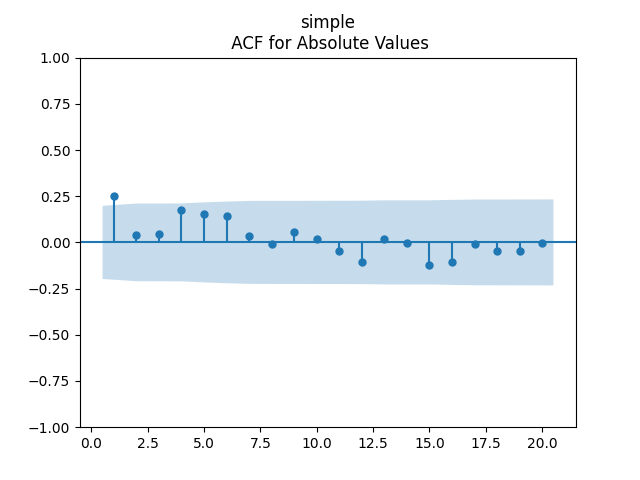
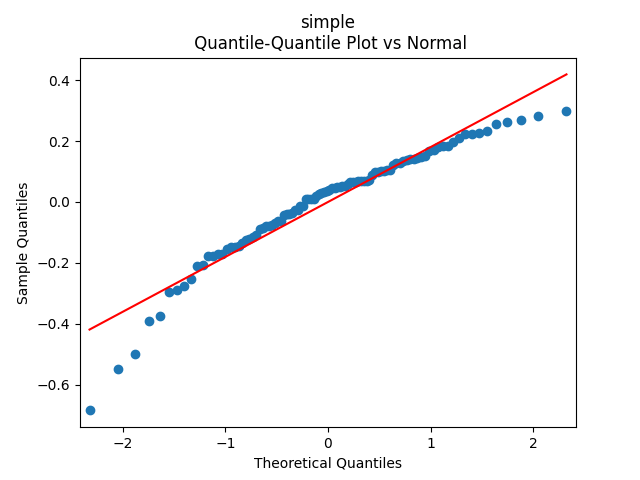
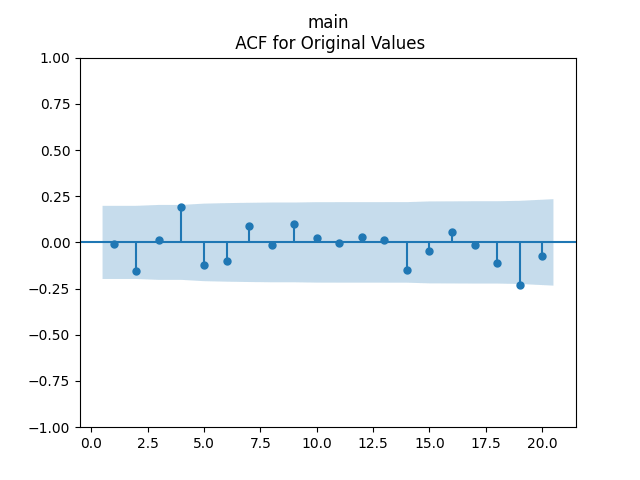
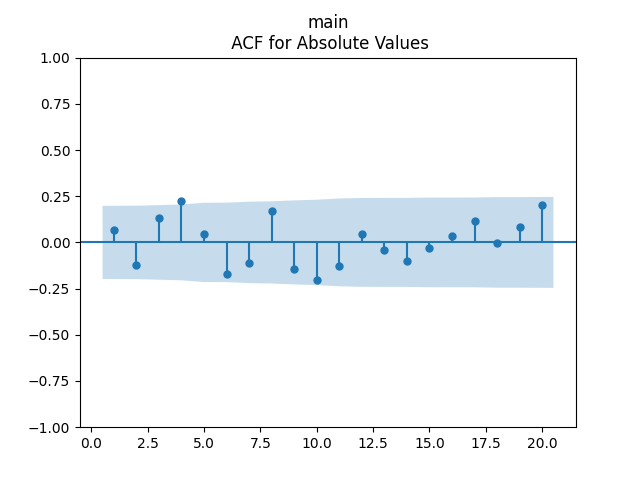
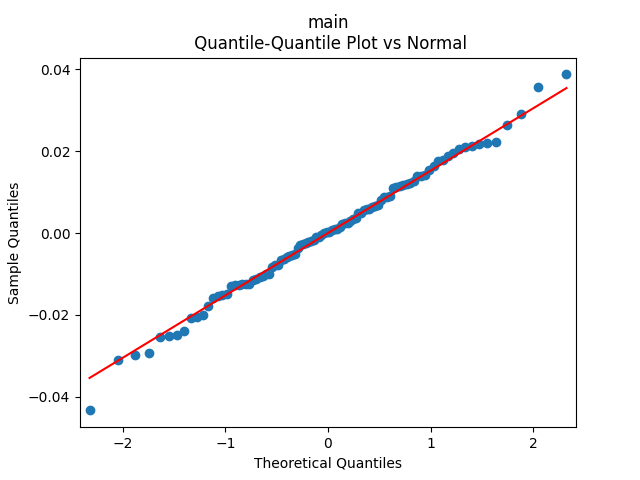
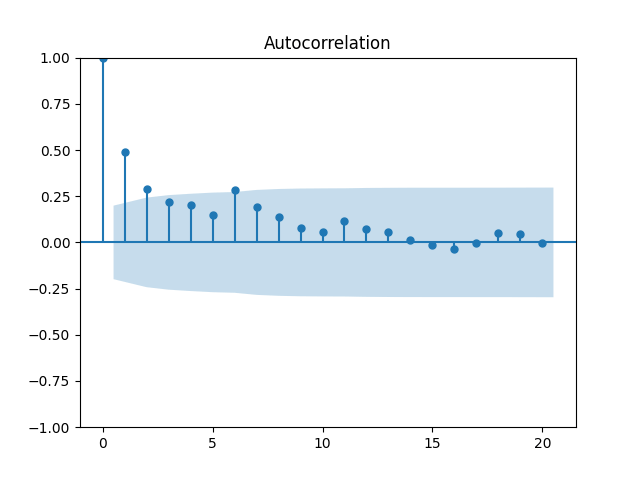
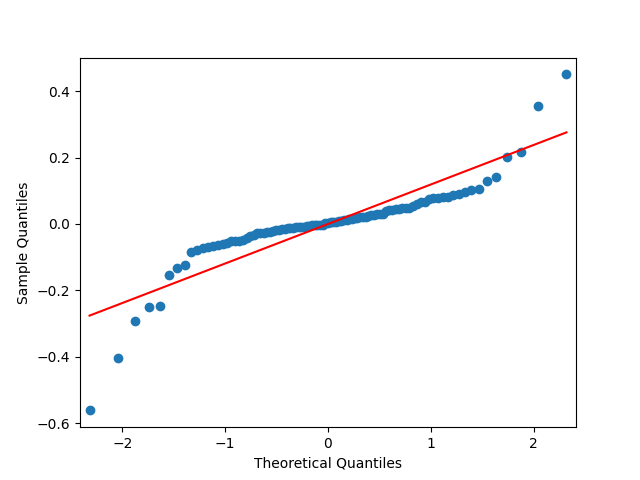
Analysis of residuals: See the autocorrelation function plots for 



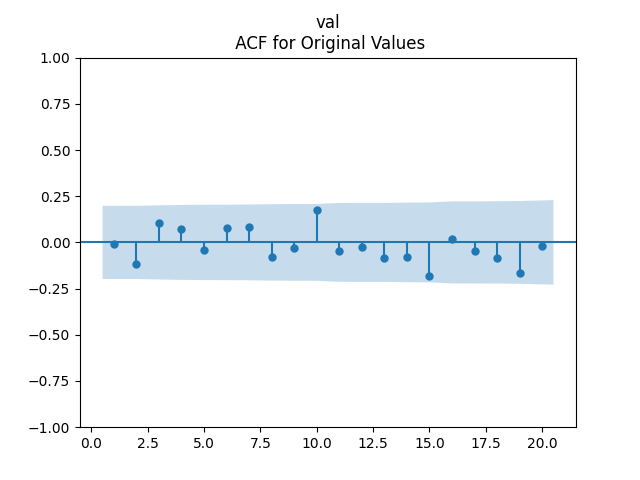
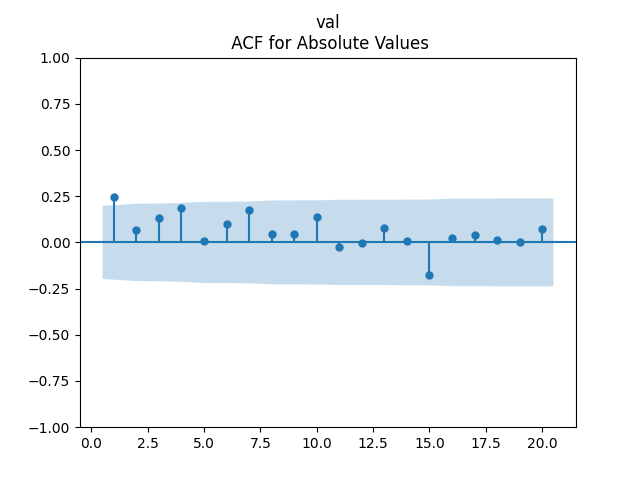
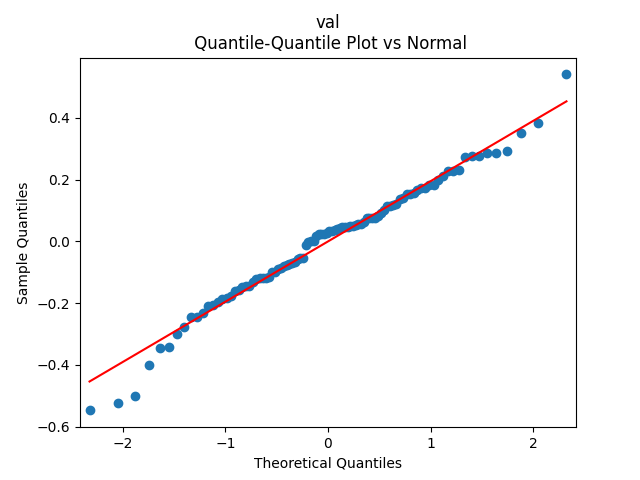
We can approximately assume that residuals are independent identically distributed Gaussian, although the autocorrelation function for lag 1 for the absolute values of innovations raises questions.
3. Use this valuation measure for modeling returns. We can model total stock returns 
Model 1. Since we know how to model dividend growth from the previous blog post, together with annual volatility, we can simply model stock returns using three time series:
- the new valuation measure
as autoregression
- volatility
as another autoregression on the log scale
- normalized dividend growth
as yet another autoregression
Model 2. However, we can also regress 

We get 



This model uses four time series, but with only three series of innovations:
- returns
regressed upon last year’s new valuation measure
- the new valuation measure
- volatility
- normalized dividend growth
as yet another autoregression
The second time series is without new innovations: Indeed, we simply write 
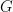
Model 3. Let us modify Model 2 to include division by volatility: We divide by

We get 


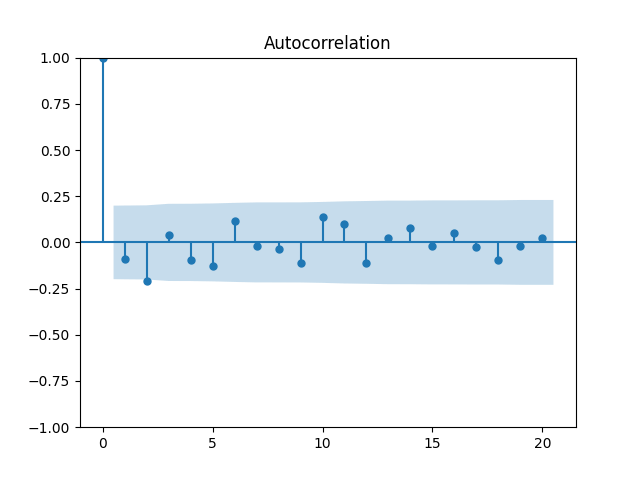
This model also uses four time series but with three series of innovations, as in Model 2.
4. Include bond rates and duration. Following the previous blog post, we include rate change 

Model 1. Try to include this rate change as a factor in dividend growth model 

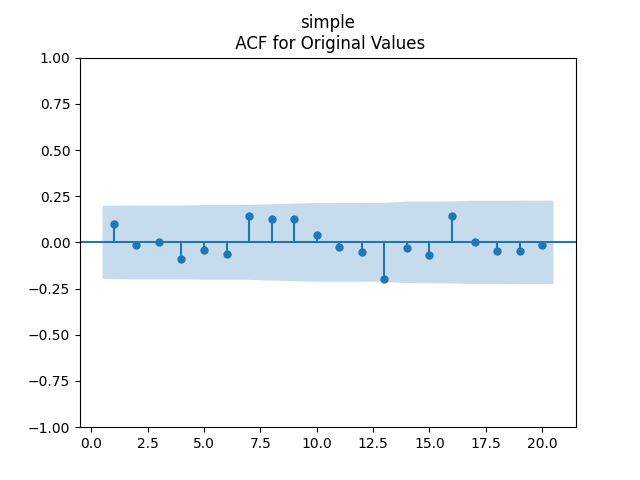
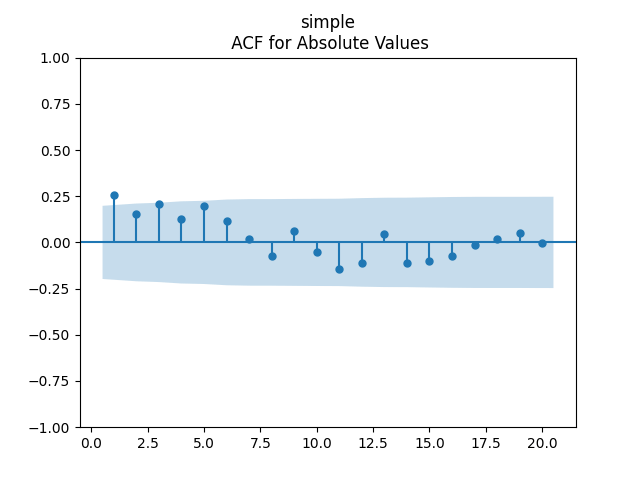
But we run into problems: The coefficient 


Similar results are if 
Finally, try to include 


Conclusion: We failed to model normalized dividend growth using rate or rate change for BAA bonds.
Model 2. Include duration in the regression for total returns, together with the valuation measure:

We get 


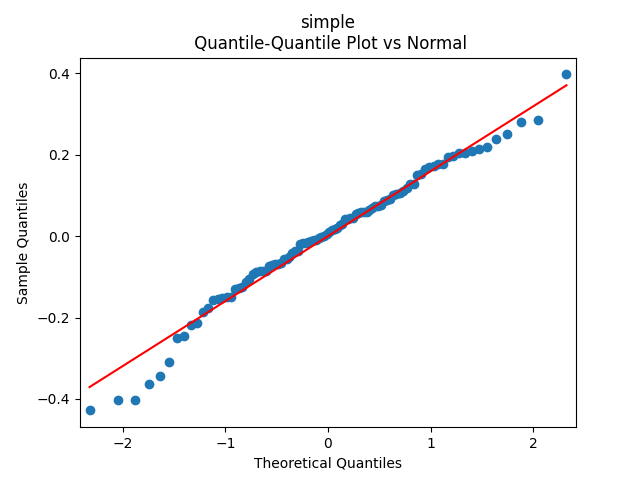
Conclusion: We failed to include duration in total returns modeling without normalizing by volatility.
Model 3. Include duration in the regression for total returns, together with the valuation measure:

We get a much better fit than without the duration or in Model 2: 



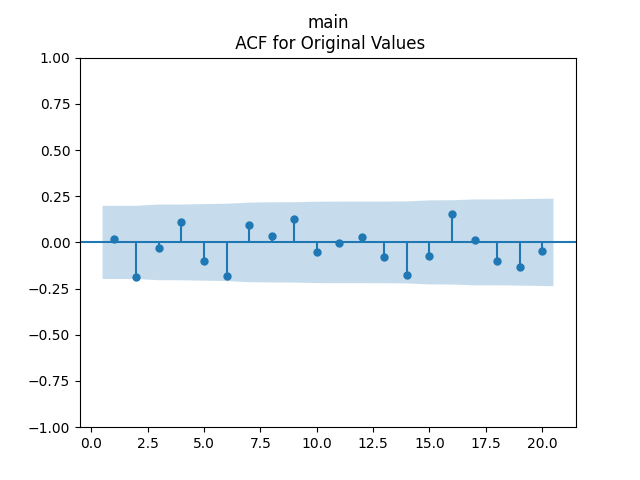
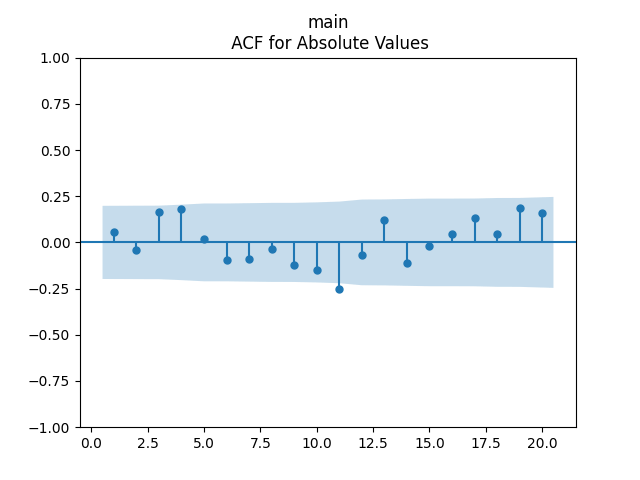
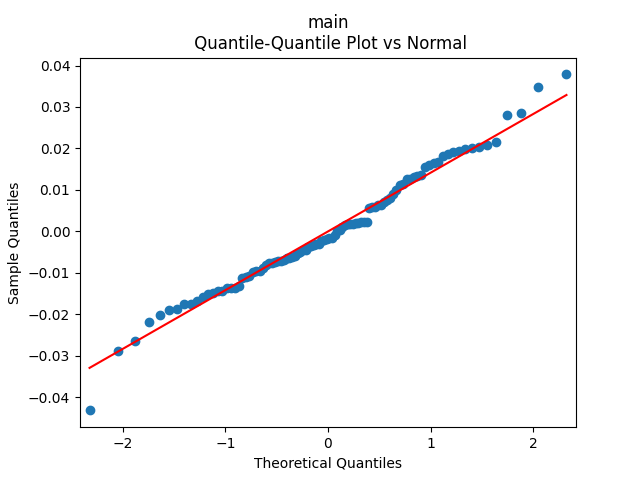
Conclusion: Here we succeeded in including the duration as a factor for regression modeling of total returns after normalizing.
5. Conclusion: We can reasonably model the new valuation measure using one-year dividends, not trailing ten- or five-year earnings, as in previous articles or blog posts. This might be better, since in previous models we used both dividends and earnings, but here we use only dividends. It is useful to include rate change as a factor in a regression for total returns, but only after normalizing, and not for normalized dividend growth. This updates our blog post. In the next post, we consider total corporate bond returns modeling using bond rates.

Leave a reply to Bond Returns 1973-2025 – My Finance Cancel reply