This is the usual disclaimer for risky financial products, found at every investment company web site.
The performance data shown represent past performance, which is not a guarantee of future results. Investment returns and principal value will fluctuate so that investors’ shares, when sold, may be worth more or less than their original cost. Current performance may be lower or higher than the performance data cited. The performance of an index is not an exact representation of any particular investment, as you cannot invest directly in an index.
Assets represented by these portfolios and indices in the simulator are not guaranteed and protected by the US government, including Federal Deposit Insurance Corporation, and may lose value, including the loss of principal.
I, Andrey Sarantsev, PhD, the creator of this simulator, discount any responsibility, legal or otherwise, resulting in the use of this simulator. Any harms, losses, or damages resulting from this use are the responsibility of the user, not me.
For professional advice on investments or retirement, speak to your financial adviser or retirement adviser.
See my GitHub repository simulator-current for the HTML frontend pages, Python backend code in Flask, Excel data file, and Python code for validation of the model described below.
Continuing the previous post, we updated the financial simulator to make for geometric returns instead of arithmetic returns. We had mistakenly made linear regression for arithmetic returns, but this does not work well, since such returns can be only greater than . Thus we replaced returns of all three asset classes (US stocks, developed-markets stocks, US bonds) from arithmetic to geometric. To compute portfolio returns, we later convert these geometric returns to arithmetic returns. The updated version is specified below.
Description and system of equations.
Testing innovations for white noise.
Testing innovations for normality.
Description and system of equations
We use the following autoregression equation for annual volatility for S&P 500 and its predecessor, S&P 90, computed by Angel Piotrowski:
with and
Next, we use the following autoregression for BAA rate, following previous research:
with and
We use the logarithm because otherwise the rate might become negative, even with very small probability.
We consider three classes of assets and denote their annual geometric total returns (multiplied by 100 for normalization):
USA stocks, measured by Standard & Poor 500 index and its predecessor, the Standard & Poor 90 index
International stocks, measured by MSCI EAFE (Europe/Australasia/Far East) index
USA corporate investment-grade bonds, measured by Bank of America ICE index (ratings AAA, AA, A, BBB)
We normalize the two stock returns by dividing them by annual volatility. But we do not normalize the bond returns. We have the following equations for these three classes of assets:
For USA corporate bonds, following this blog post, we get: with and
For USA stocks, following this blog post, we get: with and and
For international stocks, similarly to USA stocks, we get: with and and
Thus all three classes of assets have returns highly dependent upon change in interest rates, with duration (regression coefficient) for returns Note that and
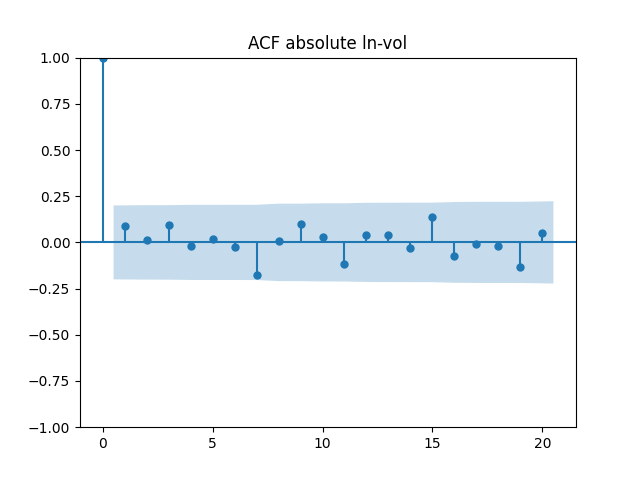
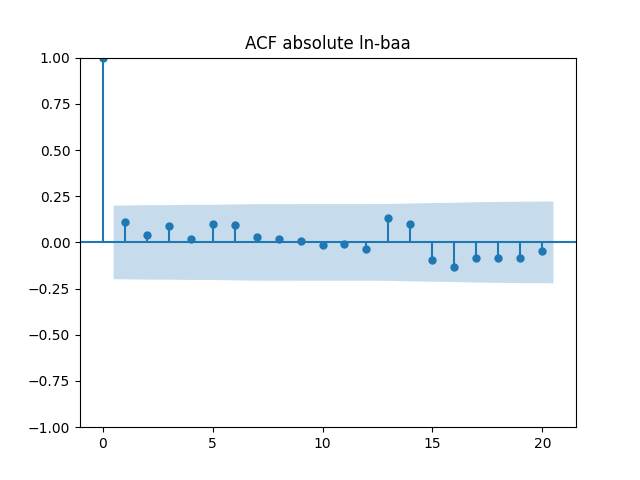
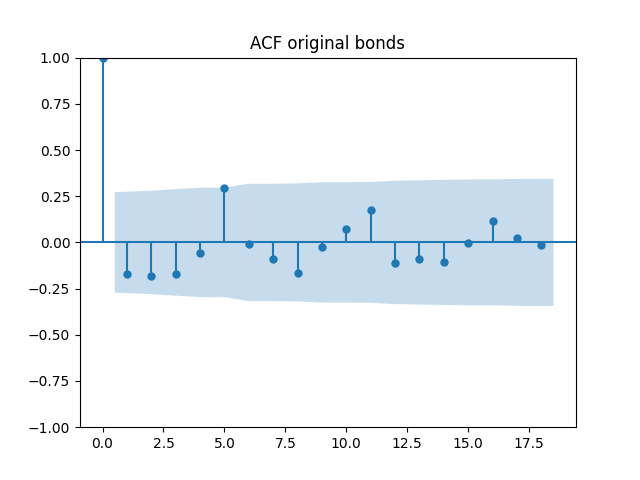
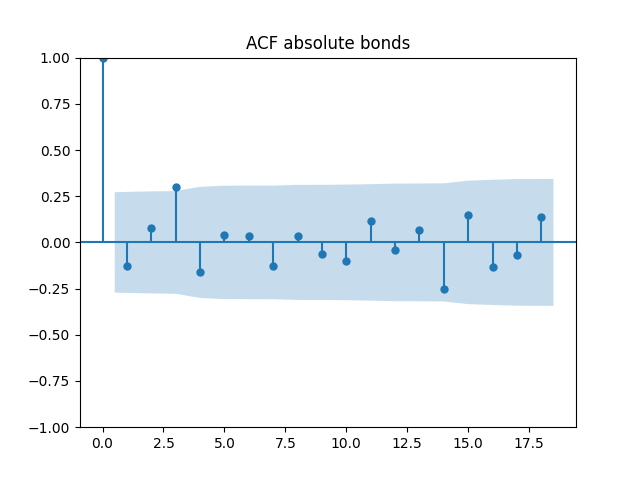
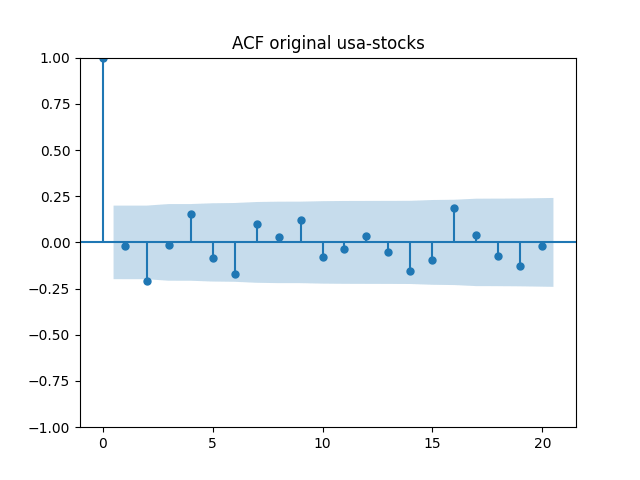
All five series of residuals are well-modeled by independent identically distributed random variables, judging by Monte Carlo simulation. I present the autocorrelation plots for them and their absolute values below.
Unfortunately, they are not normal. Namely, and (the innovations for factor autoregressions) are closer to skew-normal. I did not yet pursue this direction of research. But the other three residual series are Gaussian. I discuss their normality below.
However, I still modeled these five series as multivariate Gaussian with mean vector zero and the following empirical covariance matrix.
We consider only nominal, not real returns. To compensate for that, withdrawals/contributions can change annually.
We allow for constant split between US and international stocks. Bond and overall stock percentages might change from year to year linearly. This is to allow for a more conservative portfolio as time goes.
Also, and very importantly, we added a separate web page with a simplified version of this simulator. We describe it in a separate post.
Initial value for volatility is taken as average daily close VIX June 1, 2024 – May 31, 2025. The initial value for the BAA rate is taken as average daily May 2025.
Testing innovations for white noise
Below are autocorrelation function plots for the five series of innovations. Original and absolute in the captions refer to whether innovations are taken as is or after taking absolute values.
has tag ln-vol
has tag ln-baa
has tag bonds
has tag usa-stocks
has tag intl-stocks
Also, we compute L1 norms for first 5 values of the ACF, for original innovations and their absolute values. Comparing with these threshold values, we see that it is reasonable to model these as independent identically distributed.
N Data Points
96
97
52
97
55
Innovations
Original
0.40
0.18
0.88
0.48
0.49
Absolute
0.24
0.36
0.71
0.43
0.58
Testing innovations for normality
Similarly, we plot the five quantile-quantile plots versus the normal distribution below. Tags are the same.
Also, see p-values for statistical testing for normality: Shapiro-Wilk (SW) and Jarque-Bera (JB) testing.
Test
SW
0.9%
0.6%
86%
42%
99%
JB
6.1%
0.009%
80%
66%
90%
Finally, let us provide skewness and kurtosis for these innovations, normalized so that for the normal distribution they are 0.
Function
Skewness
0.59
0.81
0.19
0.23
-0.13
Kurtosis
0.057
1.4
0.24
0.068
0.13
Summary: are well modeled by normal, but and are not.
We have updated annual simulator. The current version uses two factors: S&P 500 volatility and BAA bond rate. Initial factors are from May 2025. We simulate portfolio of three classes of assets:
Standard & Poor 500 USA Stocks
MSCI EAFE Developed Markets Index Stocks
USA Investment-Grade Corporate Bonds, ICE Bank of America Index
We use the following autoregression equations for factors:
with and
with and
For corporate bonds, US stocks, and international stocks, denote their annual arithmetic total returns in % as
with and
with and and
with and and
All five series of residuals are well-modeled by independent identically distributed random variables, judging by Monte Carlo simulation. Unfortunately, they are not normal. Namely, and (the innovations for factor autoregressions) are closer to skew-normal. I did not yet pursue this direction of research. But the other three residual series are Gaussian.
However, I still modeled these five series as multivariate Gaussian with mean vector zero and empirical covariance matrix
We consider only nominal, not real returns. To compensate for that, withdrawals/contributions can change annually.
We allow for constant split between US and international stocks. Bond and overall stock percentages might change from year to year linearly. This is to allow for a more conservative portfolio as time goes.
We use May 2025 averages for initial factors: volatility (using rescaled VIX) and rate.
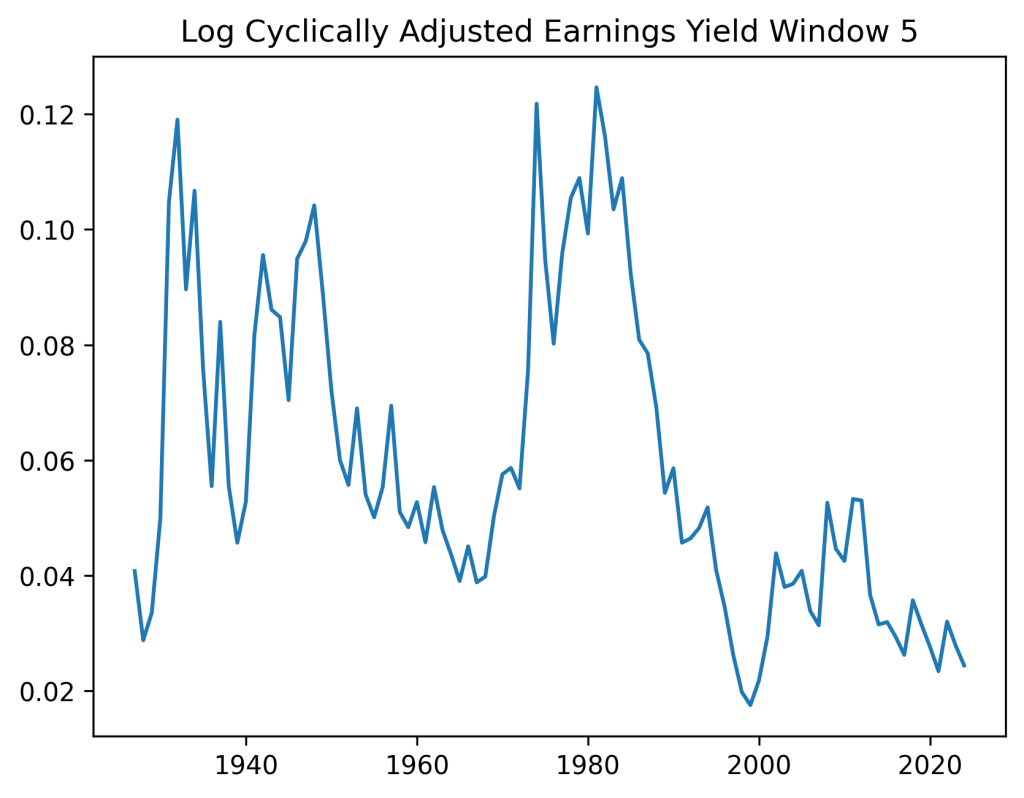
We do comparison of the new valuation model with or without volatility, for nominal or real version of earnings. We discuss which has the best innovations, according to the L1 norm of the autocorrelation function. We consider various averaging windows from 1 to 10.
Methodology: We reject the model if one of two of these norms, for original and absolute values of innovations, is greater than 0.63. W (white noise) = fail to reject. And G = Gaussian, F (fat tails) = not Gaussian (at least one of two Shapiro-Wilk and Jarque-Bera tests gives us We put results in the first table. The second table gives us in percentage.
Vol?
Infl?
1
2
3
4
5
6
7
8
9
10
No
Nom
W F
W G
W G
W F
Reject
Reject
Reject
Reject
W F
W F
No
Real
W F
W G
W G
W G
W G
W G
W G
W G
W G
W F
Yes
Nom
W G
W G
W G
Reject
Reject
Reject
Reject
Reject
Reject
Reject
Yes
Real
W G
W G
W G
W G
W G
W G
W G
Reject
Reject
Reject
Vol?
Infl?
1
2
3
4
5
6
7
8
9
10
No
Nom
17
12
11
10
10
10
10
9
9
10
No
Real
17
12
11
10
9
9
9
9
9
9
Yes
Nom
21
21
22
24
26
26
27
27
27
29
Yes
Real
21
21
22
23
25
24
25
25
25
26
Conclusion: The best model for real version is with volatility, lags 5-7. The best model for nominal version is with
See the GitHub repository file bubble-selection.py and the data file century.xlsx.
Description: Let be nominal or real total returns during year Let be the annual volatility during year Let be the BAA rate at end of year
We consider two models, both for the nominal and the real versions of returns.
Model 1.
Model 2.
Results: In each of the four models, residuals are IID Gaussian, judging by the normality tests and the autocorrelation function plots.
But what is the goodness of fit? We get for nominal Model 1 and for real Model 1. But for nominal Model 2, and for real Model 2.
Regression results are: The coefficient is insignificant judging by the Student T-test, but is significant. In both versions of Model 2, significantly different from zero. For Model 2, actually for the nominal version and for the real version.
Conclusion: We prefer Model 2, when the is much higher.
Replicate this blog with real corporate bond returns, after adjusting for inflation. We will replace (nominal) bond rates with real rates: Subtract past year’s inflation from the end of past year rate. This will be enough for an autoregression of rates. But for bond returns, we might include both nominal rate and inflation rate. Update: We failed to do this, since for the simple regression of real returns minus real rates vs duration. This is too low, and adding volatility does not improve this. See the GitHub/asarantsev repository Corporate-Bonds-Annual-Data. To be fair, residuals are IID normal for all these regressions, but this doesn’t matter.
We need to model inflation separately, presumably as an autoregression process with volatility: If is the inflation rate in year then try or Update: We used data 1928-2024 and failed. All autocorrelation plots are unacceptable, and residuals never follow normal distribution. All normality tests fail, and the autocorrelation function L1 norm for first 5 lags are not compatible with IID assumption. See the GitHub/asarantsev repository Inflation-Modeling-1928-2024 for data and code. Strange, because we have both nominal and real returns divided by volatility modeled as IID Gaussian. So the difference between them: inflation/volatility should be IID Gaussian.
Include these rates in the new valuation measure modeling of stock market returns. For real returns, pick real rates. for nominal returns, include nominal rates. Or maybe include both rates, real and nominal? Equivalently, include nominal rate and last year’s inflation.
Is the distribution of residuals important? (a) simulate using kernel density estimation with Silverman’s bandwidth. Unfortunately, we cannot rely on existing functions in Python: They can only make identity covariance matrix of simulated data. (b) simulate using multivariate normal distribution with covariance matrix estimated from the data. Then compare average total returns. This will answer the second question from this post.
Add small stocks to our research, replicating this manuscript. We can then fix capitalization ratio to the benchmark, for example 10 times smaller capitalization than S&P 500.
Then we need to update the simulator accordingly. First, we create a complete version in Python, when we can change initial values and the simulation of residuals. Second, we create a simplified version of this simulator as a web app. We will have two sliders: (a) Stocks size; (b) Bonds vs stocks.
We could make a similar slider for bond ratings, but it’s hard to quantify bond ratings similarly to stock size.
This post is continued from the previous post, which in turn continues the two posts of annual Bank of America-rated bond rates and returns. We fit the 1996-2024 data for corporate bond returns and rates.
Here, we talk about investment-grade corporate bonds in general, combining all four investment-grade ratings: AAA, AA, A, BBB. Below see the graph of these corporate bond rates, together with rates of each ratings of investment-grade bonds: AAA, AA, A, BBB. We see that investment-grade rates are closer to A or BBB, rather than AAA.
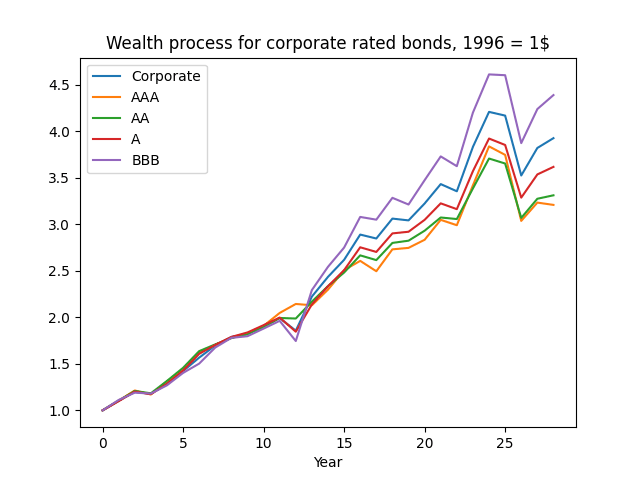
Next, plot the wealth. Then we see the same pattern. We are curious why investment-grade corporate bonds behave closer to lower-rated investment ratings, rather than AAA? Maybe there are not so many AAA rated bonds.
This might be the reason why in this post AAA rates do not predict corporate bond returns very well. Remember, we have data for Bank of America bond rates only from 1996 (end of year).
We have Bank of America investment-grade corporate bond returns starting from 1972. This discrepancy gives us motivation to use end-of-year weekly data for Moody’s AAA or BAA (which corresponds to BBB in Bank of America ratings) available from 1962 to predict investment-grade corporate bond returns. This gives us motivation to replace AAA with BAA Moody’s rates.
Using the cut data from 1996, we replicated results of annual Bank of America-rated bond rates and returns. The results are the same as for AAA, AA, A, or BBB. Using annual volatility makes the two regressions have IID Gaussian residuals. All is good, except the rates are available only from 1996.
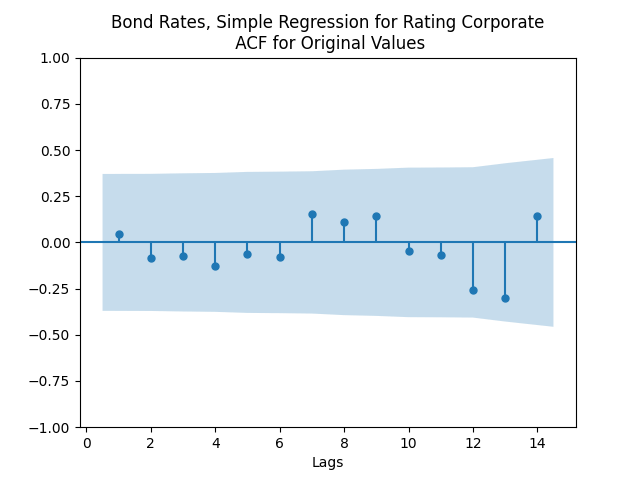
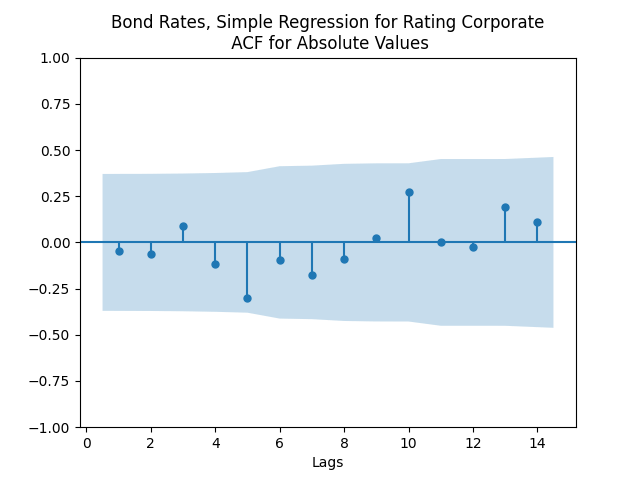
Here analysis of simple autoregression residuals for rates show they are IID but not Gaussian.
But autoregression with volatility: show these residuals are IID Gaussian. The and coefficient estimates are The Student T-test gives us for for and for The Jarque-Bera and Shapiro-Wilk The L1 values for original and absolute values of the autocorrelation function are
Model total bond returns using duration: We see residuals below.
But for the simple regression without volatility we get the following residuals:
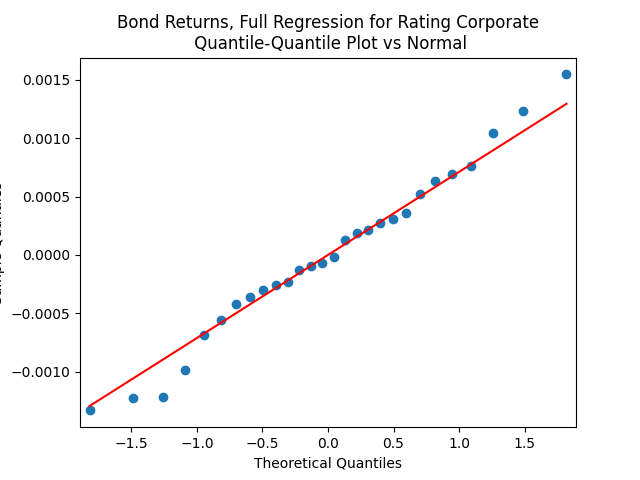
Both regressions actually have IID Gaussian residuals, judging by Shapiro-Wilk and Jarque-Bera normality tests, and the L1 values for autocorrelation function. For the simple regression, and The value of See the Python code and Excel data (updated) at https://github.com/asarantsev/Annual-Bank-of-America-Rated-Bond-Data
The simple autoregression for rates judging by the Shapiro-Wilk and Jarque-Bera tests, is better:
Look at residuals for autoregression for rates with volatility:
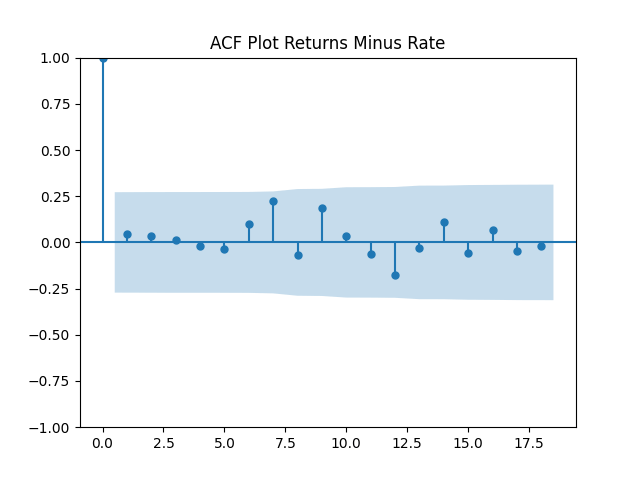
For the simple autoregression, Shapiro-Wilk and Jarque-Bera tests give us and But for the autoregression with volatility, this gives us and To be fair, from the quantile-quantile plot it is hard to tell the difference. Next, for returns minus rates if we do not regress them upon anything but simply analyze them, surprisingly, we get the IID Gaussian.
But it’s good to regress these differences upon the change in rates: We get where and And the correlation is very strong: Of course, it is statistically significant. The Shapiro-Wilk and Jarque-Bera tests give us
Innovations are simulated as multivariate Gaussian, since the kernel density estimator does only independent components in the multivariate case, but we do need correlated innovation series. This is very important, since independent innovations imply higher returns. The true innovations are negatively correlated. I will write more on this in the future.
I made sure volatility from the current year not the previous year is used to model total returns. Unfortunately, I made a misprint in previous simulators. This mistake led to independent innovations instead of negatively correlated innovations.
I removed any ability to change initial conditions, instead taking just the current conditions (volatility). I also removed any ability to change how to simulate innovations (kernel density estimation or multivariate Gaussian distribution).
Unfortunately, I made the same mistake in my other simulators.
Let me mention that I also made colored background of the plot, the legend, and the input fields. They all have different colors. Finally, I removed any references to myself and model description, because I wished to save space. I do not think usual users will be interested in this. This is only the simplest model with volatility as factor only.
TO DO LIST
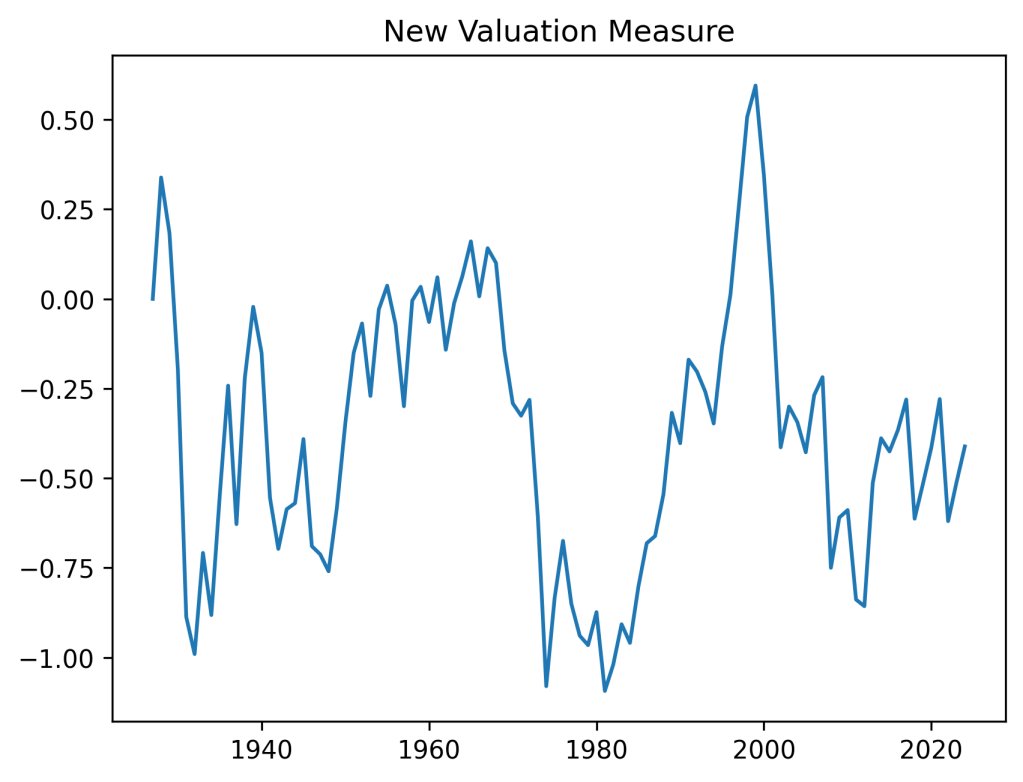
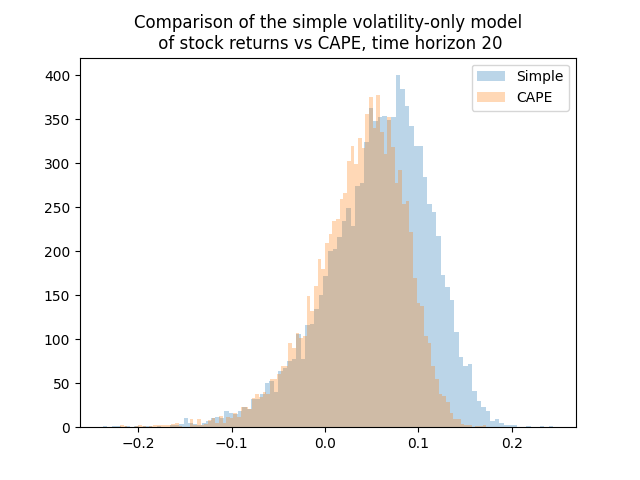
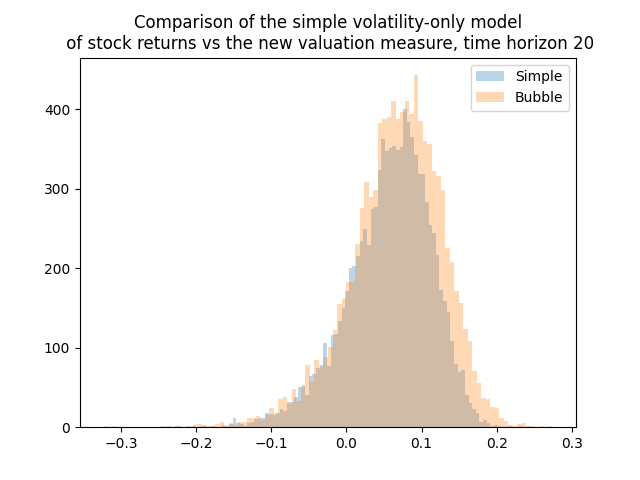
I was thinking whether adding other factors such as the new valuation measure or bond spreads changes the distribution of average total returns or terminal wealth. Because this is the only thing we are interested in. Update: See below for comparison of the simple model, CAPE, and the new valuation measure. Yes, including earnings using CAPE or the bubble measure makes a huge difference. For current CAPE, future total returns will be lower, because CAPE is way higher than the historical average. For the new bubble (valuation) measure, the opposite is true.
Use Gaussian vs Laplace innovations for autoregression of log volatility. Does this change the said distributions? If yes, we need to take care, and do kernel density estimation by hand. Volatility autoregression innovations are not Gaussian.
Need to correct these misprints in the other simulators with more complicated models.
Continuing my research program, I regress S&P returns (nominal/real, price/total) upon the new valuation measure, nicknamed the bubble, and upon the three bond spreads: BAA-AAA, AAA-Long, Long-Short. We normalize this regression by volatility in the usual way. We consider averaging windows of 5 and 10 years.
Results: Each time, innovations are IID Gaussian. The ACF plots exhibit the same strange autocorrelation at lag 4. But overall, they are consistent with white noise. Each of three spreads is insignificant, judging by the Student test. But the bubble is significant for nominal (but not real!) returns, both price and total.
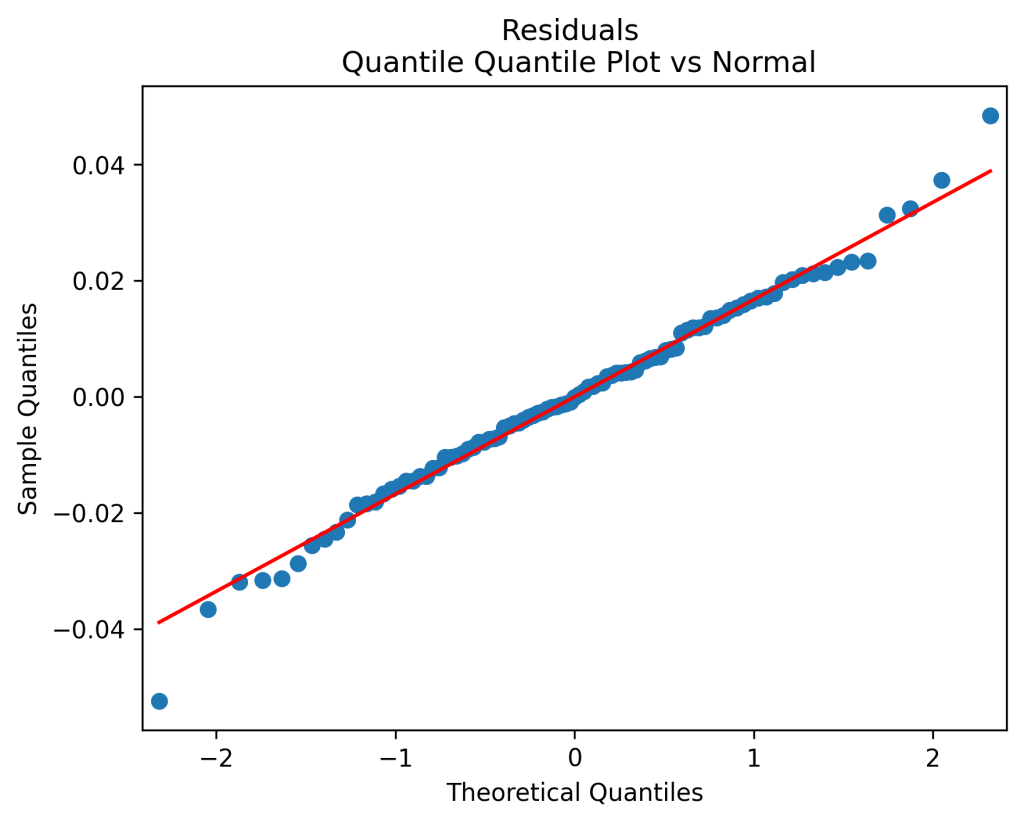
The total real returns are regressed upon the bubble and the log yield end of last year. The residuals of this regression are also normalized by volatility, so we again divide the regression equation by volatility. This time, we do add an intercept, which becomes the volatility factor. Results are as follows: the autocorrelation plots of residuals and their absolute values show that these residuals are IID, see below. The quantile-quantile plot shows these are Gaussian. Same from normality tests.
The dependence of returns upon the bubble is negative (as expected) and strong, with The dependence upon the (log) yield is, surprisingly, also negative but weak, with The dependence upon volatility is negative and very strong, with The
What if we remove the yield? The new is almost unchanged, and the adjusted version is even greater after removal. This shows superiority of the bubble upon the yield as predictor.
On the other hand, removing the bubble instead of the yield reduced and the yield factor becomes a positive predictor of total returns, but statistically insignificant, with
Finally, removing both bubble and (log) yield reduced which is not much below.
The same results are for the window 5 instead of 10.
To me, it makes sense to use either yield or bubble, but not both. This applies to the model without any other factors, or with bond spreads, or something else.
 . Thus we replaced returns of all three asset classes (US stocks, developed-markets stocks, US bonds) from arithmetic to geometric. To compute portfolio returns, we later convert these geometric returns to arithmetic returns. The updated version is specified below.
. Thus we replaced returns of all three asset classes (US stocks, developed-markets stocks, US bonds) from arithmetic to geometric. To compute portfolio returns, we later convert these geometric returns to arithmetic returns. The updated version is specified below.  with
with  and
and 
 with
with  and
and 



 with
with  and
and 
 with
with  and
and  and
and 
 with
with  and
and  and
and 
 for returns
for returns  Note that
Note that  and
and 
 are well-modeled by independent identically distributed random variables,
are well-modeled by independent identically distributed random variables,  and
and  (the innovations for factor autoregressions) are closer to skew-normal. I did not yet pursue this direction of research. But the other three residual series
(the innovations for factor autoregressions) are closer to skew-normal. I did not yet pursue this direction of research. But the other three residual series  are Gaussian. I discuss their normality below.
are Gaussian. I discuss their normality below.
 has tag ln-vol
has tag ln-vol has tag ln-baa
has tag ln-baa has tag bonds
has tag bonds has tag usa-stocks
has tag usa-stocks has tag intl-stocks
has tag intl-stocks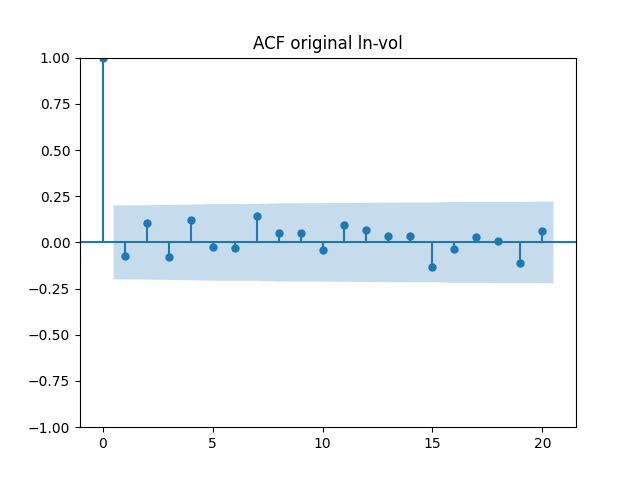

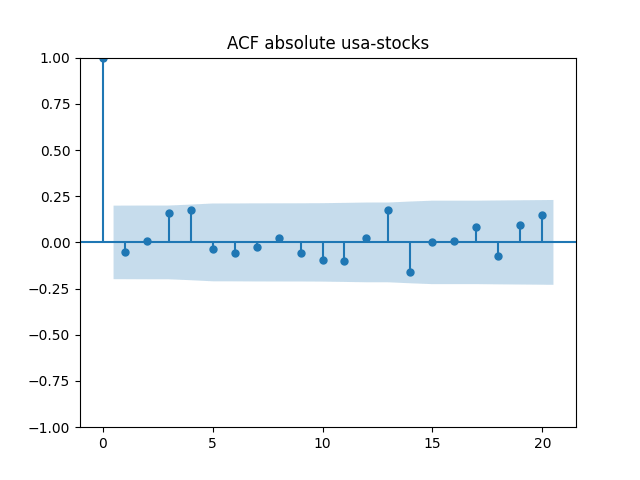
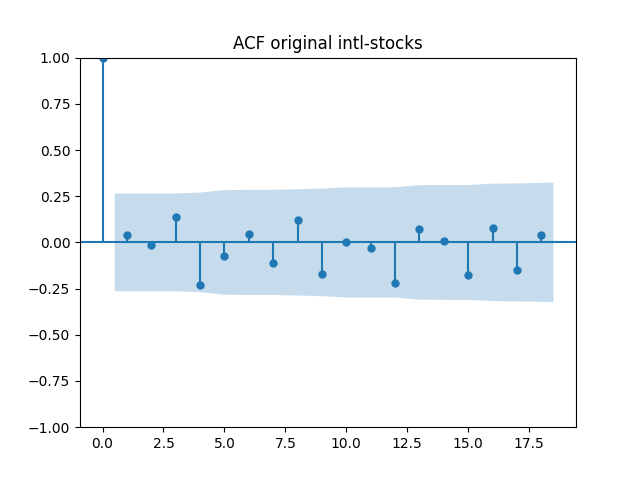
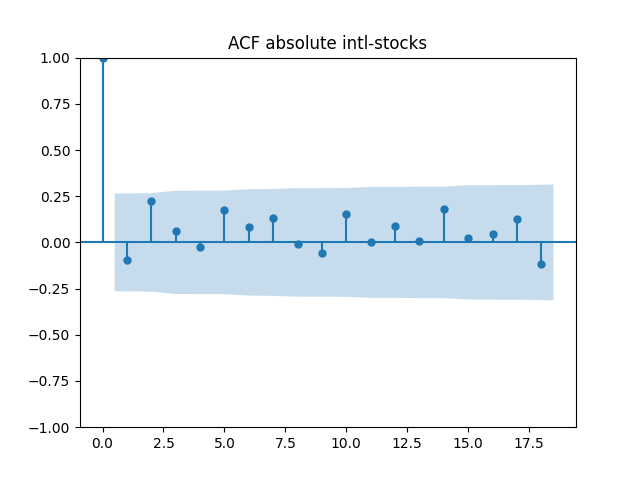


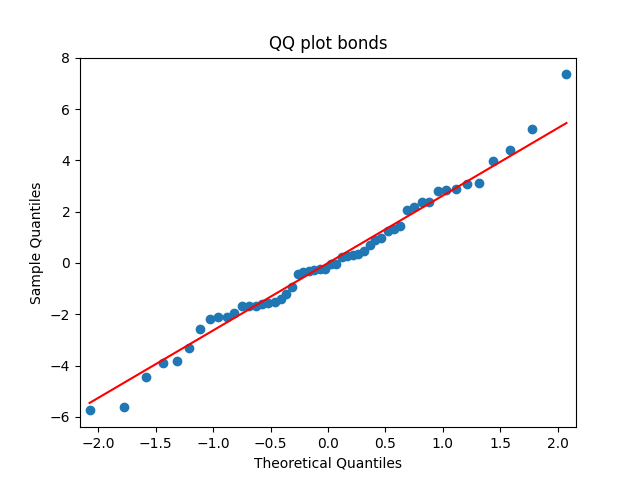
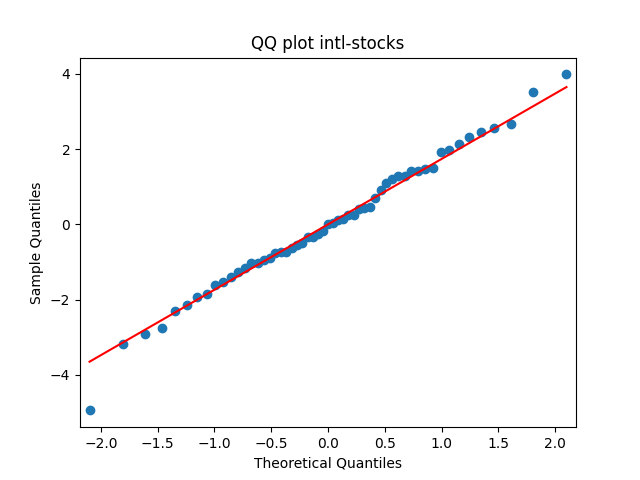
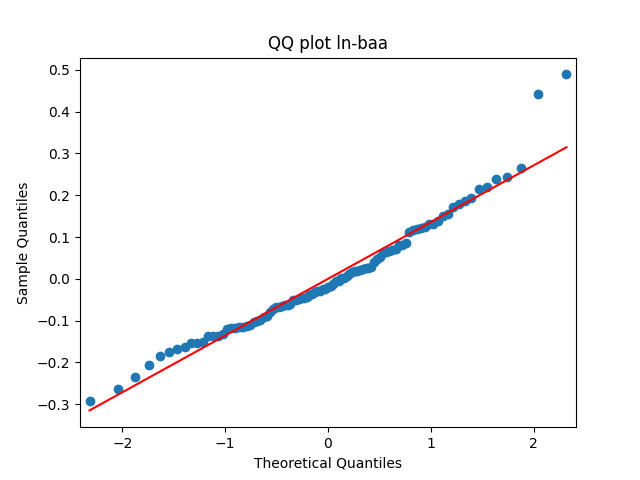
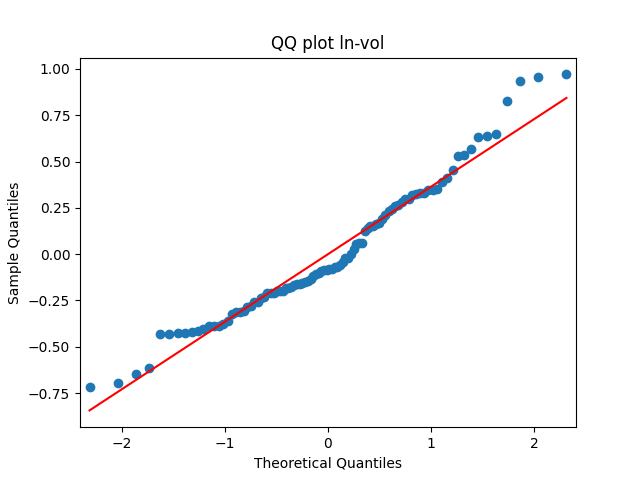
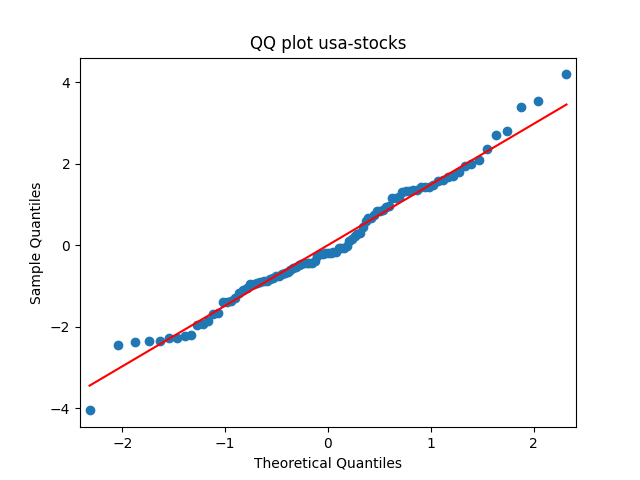
 are well modeled by normal, but
are well modeled by normal, but 
 with
with  and
and 
 and
and  and
and 
 and
and  and
and 

 We put results in the first table. The second table gives us
We put results in the first table. The second table gives us  in percentage.
in percentage. be nominal or real total returns during year
be nominal or real total returns during year  Let
Let  be the annual volatility during year
be the annual volatility during year  be the BAA rate at end of year
be the BAA rate at end of year 

 are IID Gaussian, judging by the normality tests and the autocorrelation function plots.
are IID Gaussian, judging by the normality tests and the autocorrelation function plots.  for nominal Model 1 and
for nominal Model 1 and  for real Model 1. But
for real Model 1. But  for nominal Model 2, and
for nominal Model 2, and  for real Model 2.
for real Model 2.  is insignificant judging by the Student T-test, but
is insignificant judging by the Student T-test, but  is significant. In both versions of Model 2,
is significant. In both versions of Model 2,  significantly different from zero. For Model 2, actually
significantly different from zero. For Model 2, actually  for the nominal version and
for the nominal version and  for the real version.
for the real version.  for the simple regression of real returns minus real rates vs duration. This
for the simple regression of real returns minus real rates vs duration. This  is the inflation rate in year
is the inflation rate in year  then try
then try  or
or  Update: We used data 1928-2024 and failed. All autocorrelation plots are unacceptable, and residuals never follow normal distribution. All normality tests fail, and the autocorrelation function L1 norm for first 5 lags
Update: We used data 1928-2024 and failed. All autocorrelation plots are unacceptable, and residuals never follow normal distribution. All normality tests fail, and the autocorrelation function L1 norm for first 5 lags 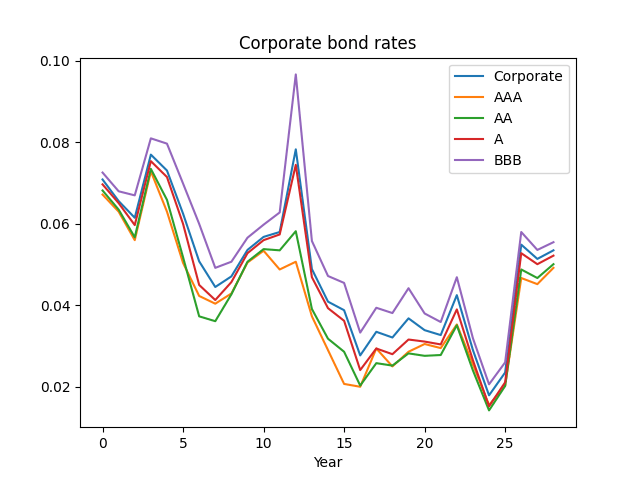
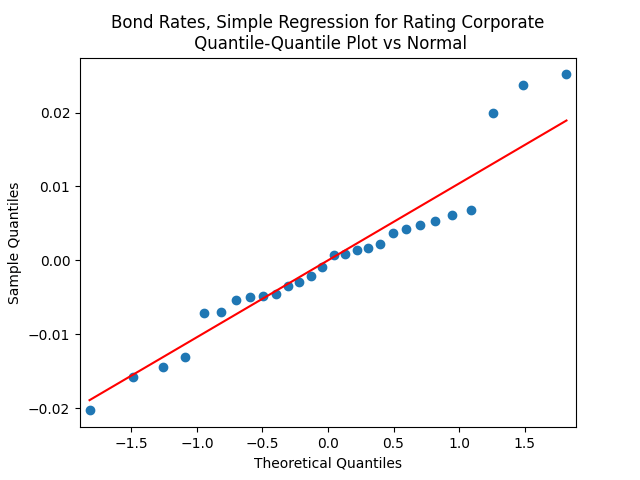
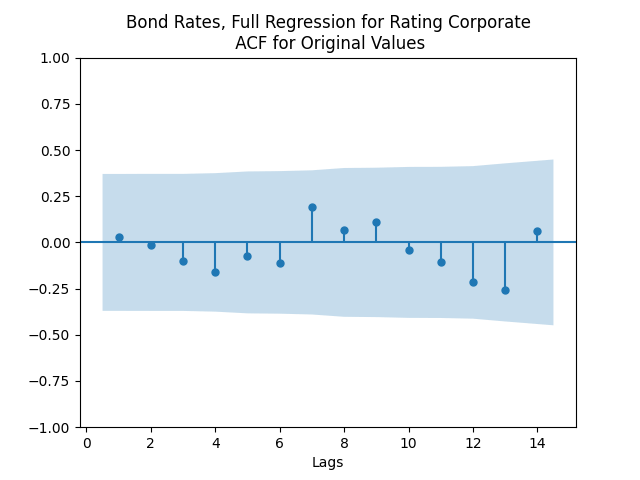
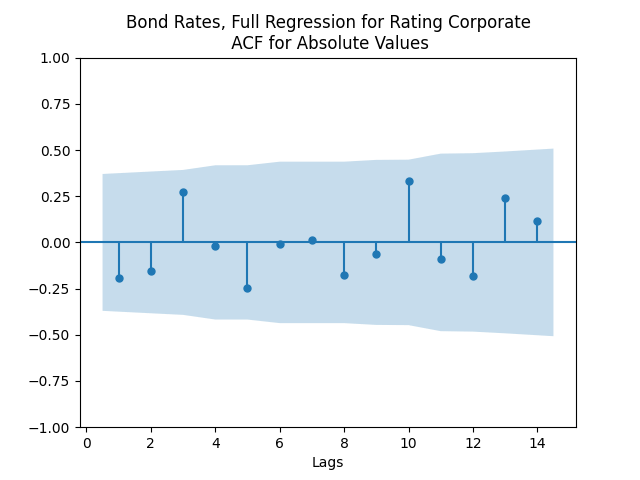
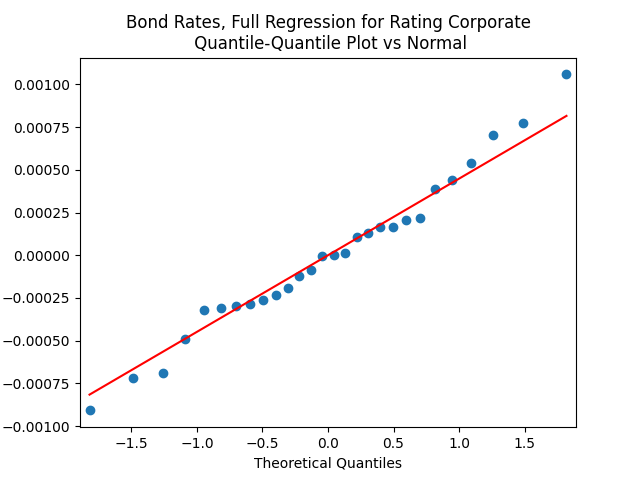
 show these residuals are IID Gaussian. The
show these residuals are IID Gaussian. The  and coefficient estimates are
and coefficient estimates are  The Student T-test gives us
The Student T-test gives us  for
for 
 for
for  and
and  for
for  The Jarque-Bera and Shapiro-Wilk
The Jarque-Bera and Shapiro-Wilk  The L1 values for original and absolute values of the autocorrelation function are
The L1 values for original and absolute values of the autocorrelation function are 
 We see residuals below.
We see residuals below. 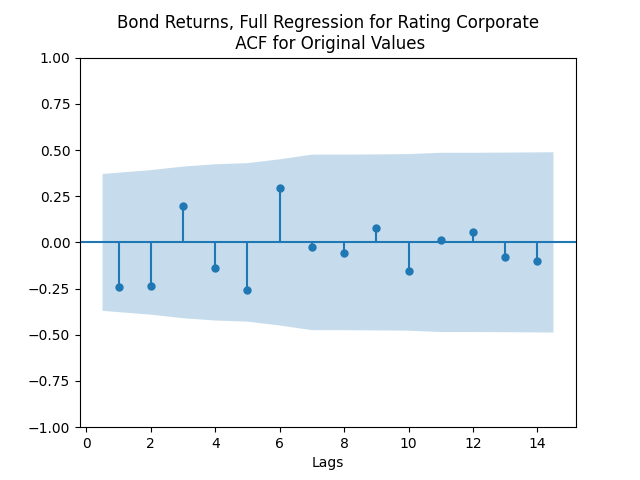
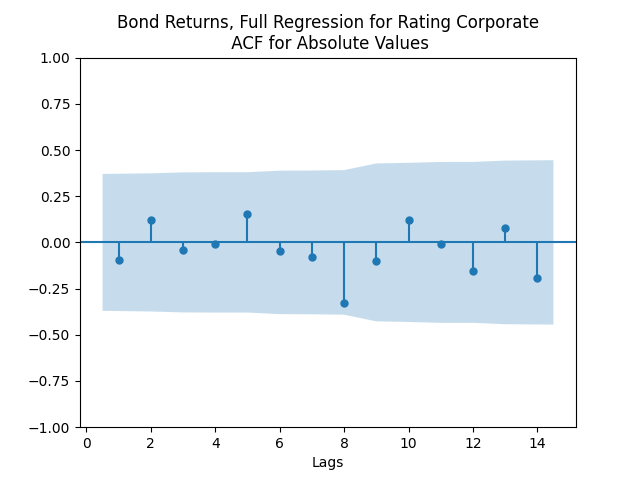
 we get the following residuals:
we get the following residuals: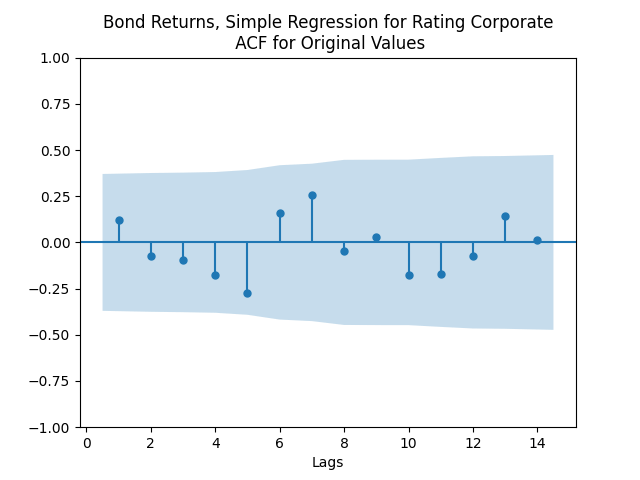
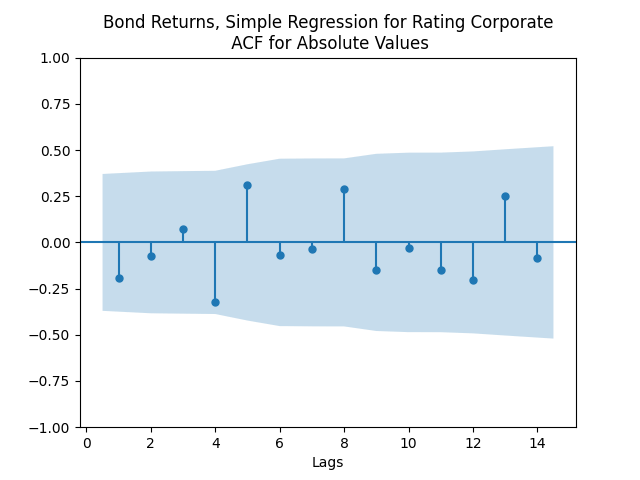
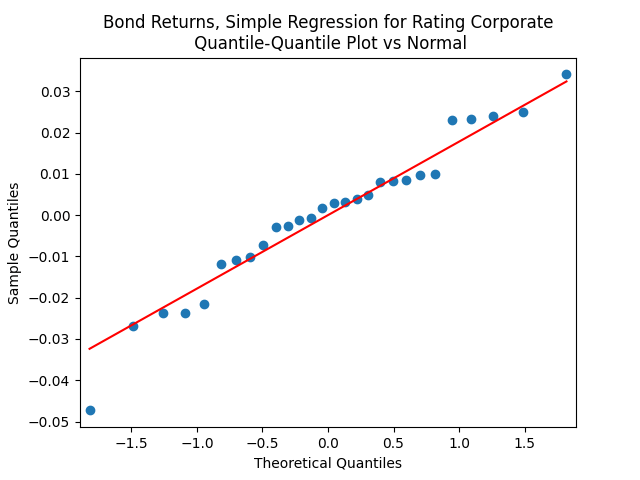
 and
and  The value of
The value of  See the Python code and Excel data (updated) at
See the Python code and Excel data (updated) at 
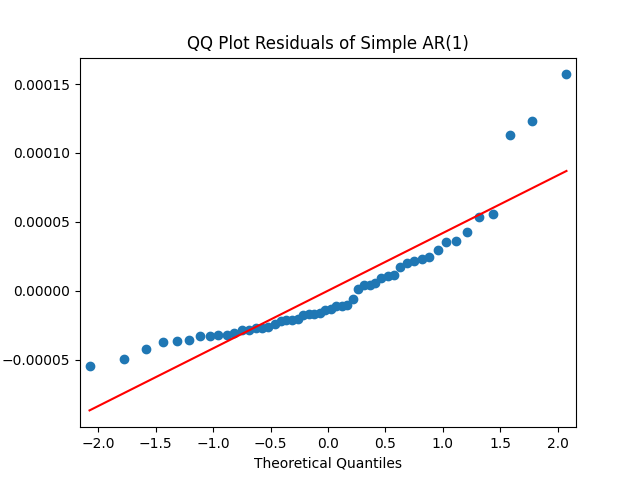
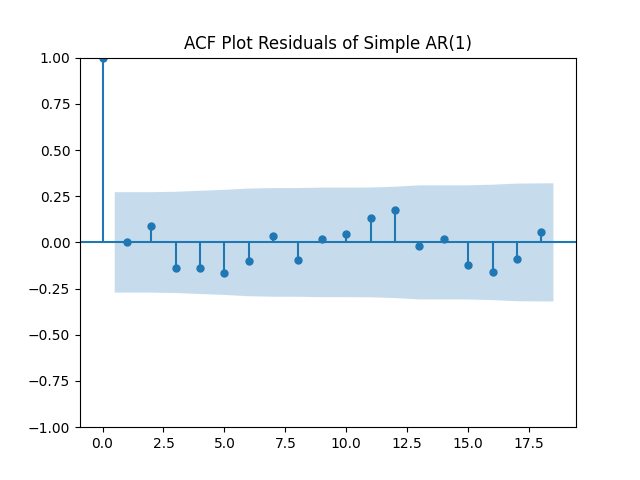
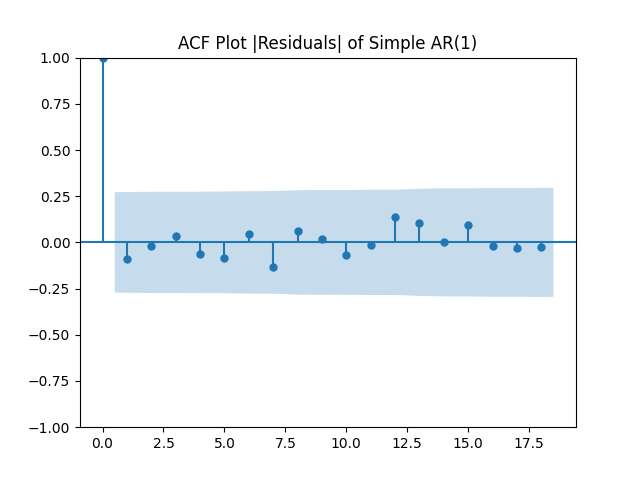

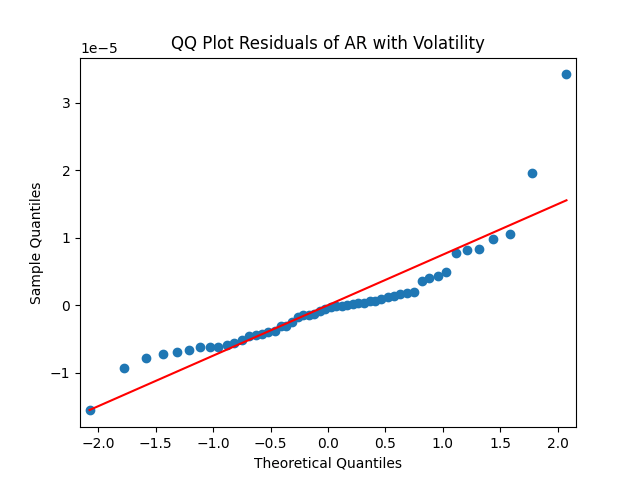
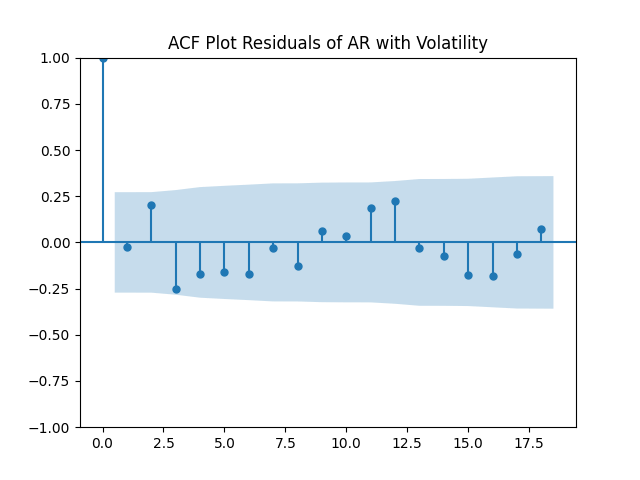
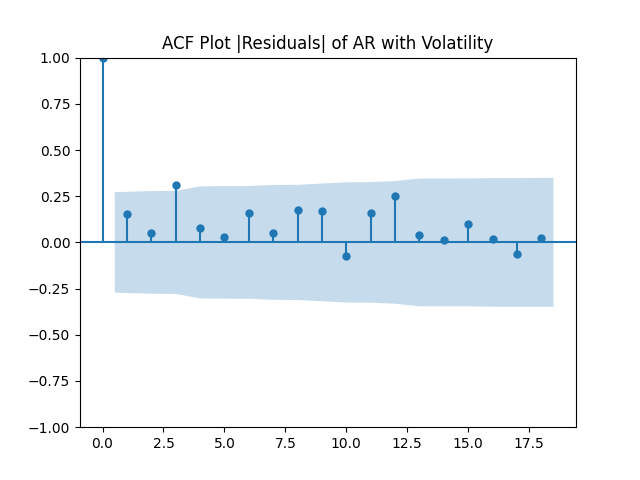
 and
and  But for the autoregression with volatility, this gives us
But for the autoregression with volatility, this gives us  and
and  To be fair, from the quantile-quantile plot it is hard to tell the difference. Next, for returns
To be fair, from the quantile-quantile plot it is hard to tell the difference. Next, for returns  if we do not regress them upon anything but simply analyze them, surprisingly, we get the IID Gaussian.
if we do not regress them upon anything but simply analyze them, surprisingly, we get the IID Gaussian. 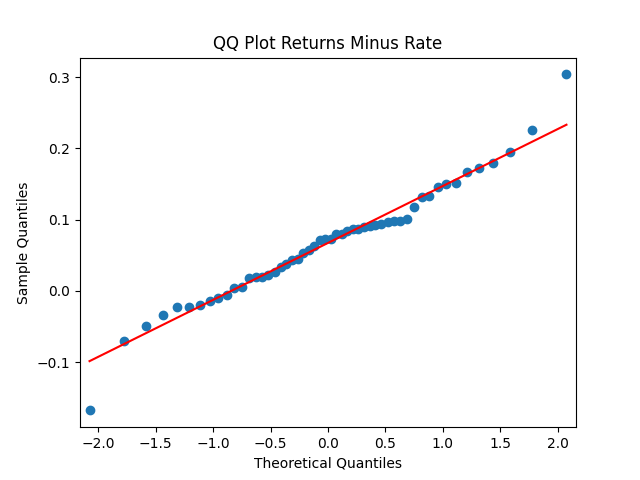

 upon the change in rates:
upon the change in rates:  We get
We get  where
where  and
and  And the correlation is very strong:
And the correlation is very strong:  Of course, it is statistically significant. The Shapiro-Wilk and Jarque-Bera tests give us
Of course, it is statistically significant. The Shapiro-Wilk and Jarque-Bera tests give us 


 The dependence upon the (log) yield is, surprisingly, also negative but weak, with
The dependence upon the (log) yield is, surprisingly, also negative but weak, with  The dependence upon volatility is negative and very strong, with
The dependence upon volatility is negative and very strong, with  The
The 
 is almost unchanged, and the adjusted version is even greater after removal. This shows superiority of the bubble upon the yield as predictor.
is almost unchanged, and the adjusted version is even greater after removal. This shows superiority of the bubble upon the yield as predictor. and the yield factor becomes a positive predictor of total returns, but statistically insignificant, with
and the yield factor becomes a positive predictor of total returns, but statistically insignificant, with 
 which is not much below.
which is not much below.