Contents: Problems; Kernel Density Estimation; Missing Data
Problems. We have non-normality of innovations. Even when they are independent identically distributed, we cannot guarantee their normality. What is more, different series of innovations have different lengths. For example, in our current version of the simulator, we have five series of innovations. They are available in the Excel file innovations.xlsx in GitHub repository asarantsev/simulator-current
- Autoregression for log volatility: 96 data points
- S&P stock returns: 97 data points
- International stock returns: 55 data points
- Autoregression for log rate: 97 data points
- Corporate bond returns: 52 data points
In the previous version of the simulator, I simply used the multivariate normal distribution. We can compute the empirical covariance matrix by ignoring the missing data. And the means are, of course, zero. But, as mentioned above, the distribution is not normal in fact. To be more precise, the first and fourth components are not normal. In particular, their kurtosis is greater than that of the normal distribution, and the skewness is nonzero.
I tried to apply other distributions to fit each of these two components: skew-normal and variance-gamma. But I failed to fit them well. What is more, fitting univariate distribution is not enough. I need to combine them with normal marginals for the other three components. I did not find relevant exact literature. This would require developing entire new theory of multivariate distributions.
Kernel Density Estimation. This is a universal nonparametric method: (KDE). We apply Gaussian kernel: For 

where 


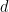
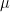







For 

Here, 




Missing Data: The other problem mentioned above is lack of data for some series of innovations. We considered many imputation methods, for example iterative imputer using Principal Component Analysis or k-nearest neighbor method. They are implemented in Python package sklearn. But such methods reduce variance, because imputed data reverts to the mean. I chose a custom designed approach. It comes in iterated steps. We describe one step below.
Step. Assume we have 
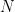


We first apply this step to one missing data point for series 1 (using series 2 and 4 as the backbone), then to 


Leave a comment